15 Parentage Analyses

The analysis of parental and offspring data
- Parentage-type analyses.
- Analyses based upon multiple paternity
Parentage analyses are used in a broad range of studies:
- Identical vs fraternal twins
- Agricultural crop line differentiation
- Differentiate between livestock/dog/cat breeds
- Pathogenic strain identification (e.g., Hep-C strains a-e)
- Assigning parentage to individuals
- Assigning individuals to populations
- Identifying the source of unknown tissues (e.g., gettin’ perps)
A statistical approach for identifying the parent(s) of a particular individual. This requires:
- A set of genetic markers that are bi-parentally inherited
- Variation in these markers
- Some assumptions about the prior probability of the union of parents.
15.1 Paternity vs. Maternity
For single parent parentage analysis, it is either paternity or maternity that is being established. Here we assume that the other parent is definitely the biological parent of the individual (e.g., \(P(prior)=1\)). This can be because:
- The offspring was collected from the identified parent
- There is other evidence that points to the identified parent being the biological one.
The goal then is to determine who the unidentified parent is with some level of statistical probability.
Terms Used in Parentage
The following terms are commonly used in parentage analyses:
Extra-Pair Paternity - Fertilization resulting from copulation outside a recognized pair bond.
Multiple Paternity - Offspring produced from mating events with different sets of individuals.
Paternity/Maternity Exclusion - Excluding an individual based upon an in-congruence in observed genetic data.
15.2 Probability of Exclusion
| Mother | Offspring | Excluded Dads | Probability |
|---|---|---|---|
| \(A_1A_1\;(p^2_1)\) | \(A_1A_1\;(p_1)\) | \(A_2A_2\;(p_2^2)\) | \(p_1^3p_2^2\) |
| \(A_1A_1\;(p^2_1)\) | \(A_1A_2\;(p_2)\) | \(A_1A_1\;(p_1^2)\) | \(p_1^4p_2\) |
| \(A_1A_1\;(p^2_1)\) | \(A_2A_2\;(0)\) | - | - |
| \(A_1A_2\;(2p_1p_2)\) | \(A_1A_1\;(\frac{p_1}{2})\) | \(A_2A_2\;(p_2^2)\) | \(p_1^2p_2^3\) |
| \(A_1A_2\;(2p_1p_2)\) | \(A_1A_2\;(\frac{1}{2})\) | - | - |
| \(A_1A_2\;(2p_1p_2)\) | \(A_2A_2\;(\frac{p_2}{2})\) | \(A_1A_1\;(p_1^2)\) | \(p_1^3p_2^2\) |
| \(A_2A_2\;(p^2_2)\) | \(A_1A_1\;(0)\) | - | - |
| \(A_2A_2\;(p^2_2)\) | \(A_1A_2\;(p_1)\) | \(A_2A_2\;(p_2^2)\) | \(p_1p_2^4\) |
| \(A_2A_2\;(p^2_2)\) | \(A_2A_2\;(p_2)\) | \(A_1A_1\;(p_1^2)\) | \(p_1^2p_2^3\) |
Probability of Exclusion
\[ P_{exc} = p_1^3p_2^2 + p_1^4p_2 +p_1^2p_2^3 +p_1^3p_2^2 +p_1p_2^4 +p_1^2p_2^3 \\ \]
which when simplified down a bit becomes
\[ P_{exc} = p_1p_2(1-p_1p_2) \]
Single Locus Paternity Exclusion
p <- seq(0,1,by=0.02)
q <- 1-p
Pexcl <- p*q*(1-p*q)
plot(Pexcl ~ p, xlab="Allele frequency, p", ylab="Paternity Exclusion Probability")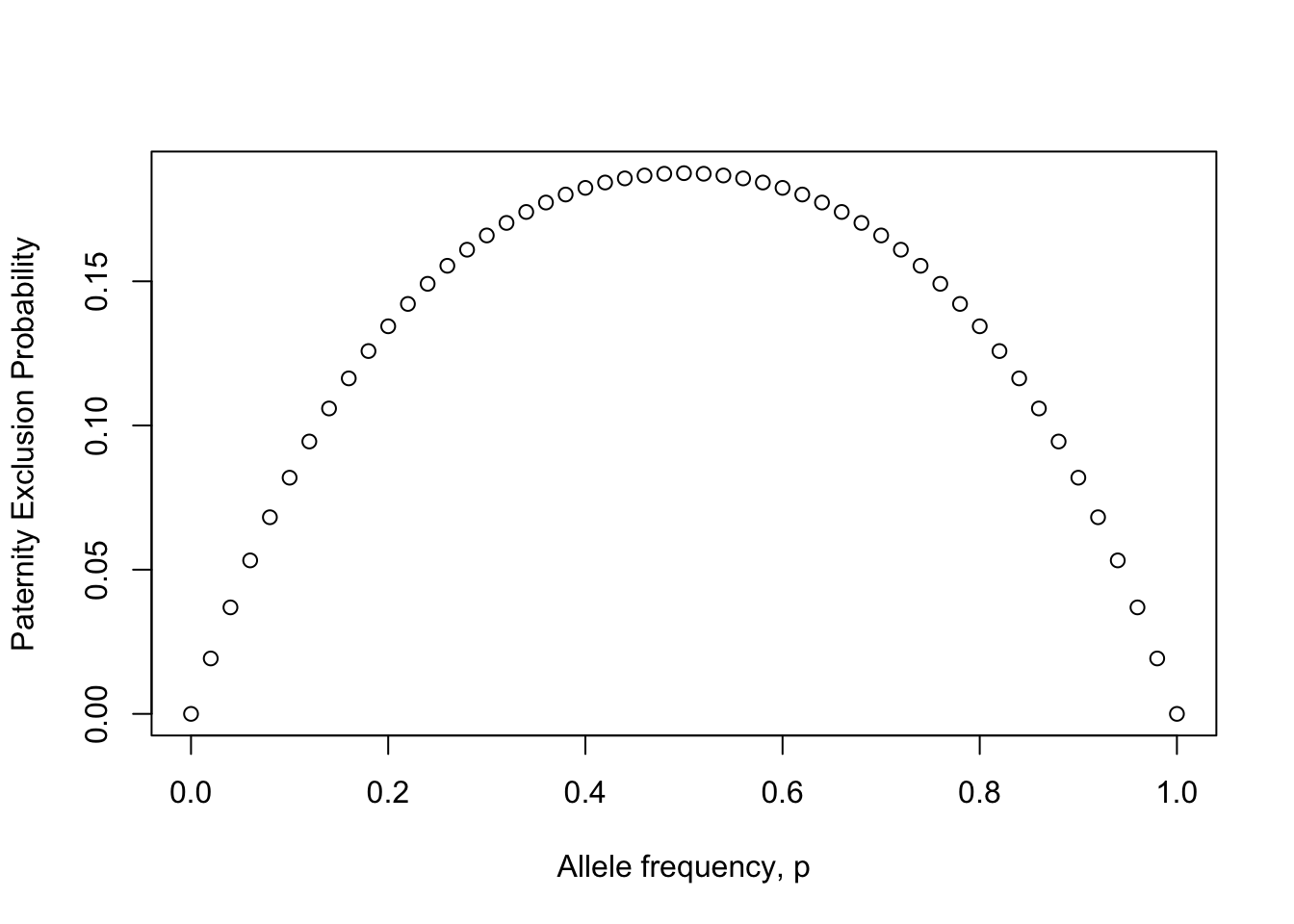
Multilocus Exclusion
Exclusion probabilities are multiplicative properties.
\[ P_{excl} = 1 - \prod_{i=1}^\ell(1-P_{excl,\;i}) \]
Example
## [1] 0.1875 0.1875 0.1875 0.1875 0.1875## [1] 0.6459074| Mother | Offspring | Excluded Father \(A_xA_y\) | Probability of Exclusion |
|---|---|---|---|
| \(A_iA_i\;(p_i^2)\) | \(A_iA_i\;(p_i)\) | \(x,y\ne i\;\; (1-p_i)^2\) | \(p_i^3(1-p_i)^2\) |
| \(A_iA_i\;(p_i^2)\) | \(A_iA_j\;(p_j)\) | \(x,y\ne j\;\; (1-p_j)^2\) | \(p_i^2p_j(1-p_i)^2\) |
| \(A_iA_j\;(2p_ip_j)\) | \(A_iA_i\;(\frac{p_i}{2})\) | \(x,y \ne i\;\; (1-p_i)^2\) | \(p_i^2p_j(1-p_i)^2\) |
| \(A_iA_j\;(2p_ip_j)\) | \(A_iA_j\;(\frac{p_i+p_j}{2})\) | \(x,y \ne i,j\;\; (1-p_i-p_j)^2\) | \(p_ip_j(p_i+p_j)(1-p_i-p_j)^2\) |
| \(A_iA_j\;(2p_ip_j)\) | \(A_iA_k\;(\frac{p_k}{2})\) | \(x,y \ne k\;\; (1-p_k)^2\) | \(p_ip_jp_k(1-p_k)^2\) |
| \(A_iA_j\;(2p_ip_j)\) | \(A_jA_k\;(\frac{p_k}{2})\) | \(x,y \ne k\;\; (1-p_k)^2\) | \(p_ip_jp_k(1-p_k)^2\) |
| \(A_iA_j\;(2p_ip_j)\) | \(A_jA_j\;(\frac{p_j}{2})\) | \(x,y \ne j\;\; (1-p_j)^2\) | \(p_ip_j^2(1-p_j)^2\) |
15.3 Paternity Exclusion
Likelihood Ratios
A likelihood ratio is given by:
\[ LR = \frac{H_P}{H_D} \]
where the \(H_X\) values are the hypotheses probabilities.
Nomenclature For Parentage
| Individual | Identifier | Genotype |
|---|---|---|
| Female Parent | \(FP_i\) | \(\alpha_i\) |
| Putative Male Parent | \(MP_j\) | \(\beta_j\) |
| Offspring | \(O_k\) | \(\gamma_k\) |
\(\;\)
Paternal Probability The posterior odds of paternity versus non-paternity given the totality of genetic information.
Likelihood Ratios | Genetic Equivalences
The likelihood of one hypothesis, \(H_1\) relative to another \(H_2\) is:
\[ L(H_1,H_2|D) = \frac{P(D|H_1)}{P(D|H_2)} \]
where
\[ P(D|H) = T(\gamma | \alpha, \beta)P(\alpha)P(\beta) \]
Assuming \(H_1:\) states that \(\beta\) is the real father of \(\gamma\) on \(\alpha\) and \(H_2:\) states that he is just a random individual in the population is:
\[ L(H_1,H_2|\alpha,\beta,\gamma) = \frac{P(D|\alpha,\beta,\gamma)}{P(D|\alpha,\gamma)} \]
which can be simplified to:
\[ \lambda_j = \frac{P(\alpha_i,\beta_j,\gamma_k|\mathrm{paternity})}{P(\alpha_i,\beta_j,\gamma_k|\mathrm{non-paternity})} \\ = \frac{P(\beta_j)P(\alpha_i)T(\gamma_k|\alpha_i,\beta_j)}{P(\beta_j)P(\alpha_i)T(\gamma_k|\alpha_i)} \\ = \frac{T(\gamma_k|\alpha_i,\beta_j)}{T(\gamma_k|\alpha_i)} \]
where \(T(X|Y)\) is the Mendelian transition probability of offspring \(X\) given parent \(Y\).
Assumptions in Model of Paternity Likelihood
The basic paternity exclusion model assumes:
- Completely random mating (can be modified by changin priors)
- Independent assortment of alleles
Likelihood Example
Consider the maternal individual whose genotypes are: \[ FP = \{AA,\;Bb,\;CC,\;Dd\} \]
Whose \(i^{th}\) offspring has the genotypes:
\[ O_i = \{AA,\;BB,\;Cc,\;dd\} \]
Likelihood Example | \(T(O|FP)\)
The transition probability, \(T(O|FP)\), is then:
| Individual | Locus1 | Locus2 | Locus3 | Locus4 |
|---|---|---|---|---|
| \(FP\) | \(AA\) | \(Bb\) | \(CC\) | \(Dd\) |
| \(O_i\) | \(AA\) | \(BB\) | \(Cc\) | \(dd\) |
\(T(O|FP) = 1*0.5*1*0.5 = 0.25\)
Likelihood Example | Putative Male Parents
| Individual | Locus1 | Locus2 | Locus3 | Locus4 |
|---|---|---|---|---|
| \(MP_1\) | \(Aa\) | \(BB\) | \(cc\) | \(Dd\) |
| \(MP_2\) | \(AA\) | \(BB\) | \(Cc\) | \(dd\) |
\(\;\)
Which one of the potential fathers is the most likely parent?
Likelihood Example | First Putative Father
| Individual | Locus1 | Locus2 | Locus3 | Locus4 |
|---|---|---|---|---|
| \(FP\) | \(AA\) | \(Bb\) | \(CC\) | \(Dd\) |
| \(MP_1\) | \(Aa\) | \(BB\) | \(cc\) | \(Dd\) |
| \(O_i\) | \(AA\) | \(BB\) | \(Cc\) | \(dd\) |
| \(T(O|FP,MP)\) | 0.5 | 0.5 | 1.0 | 0.25 |
\[ T(O_1|FP,MP_1) = 0.5 * 0.5 * 1.0 * 0.25 = 0.0625 \]
And
\[ \lambda_1 = \frac{T(O_i|FP,MP_1)}{T(O_i|FP)} = \frac{0.0625}{0.25} = 0.25 \]
Likelihood Example | Second Putative Father
| Individual | Locus1 | Locus2 | Locus3 | Locus4 |
|---|---|---|---|---|
| \(FP\) | \(AA\) | \(Bb\) | \(CC\) | \(Dd\) |
| \(MP_2\) | \(AA\) | \(BB\) | \(Cc\) | \(dd\) |
| \(O_i\) | \(AA\) | \(BB\) | \(Cc\) | \(dd\) |
| \(T(O|FP,MP)\) | 1.0 | 0.5 | 0.5 | 0.5 |
\[ T(O_1|FP,MP_2) = 0.5 * 0.5 * 1.0 * 0.25 = 0.125 \]
And
\[ \lambda_2 = \frac{T(O_i|FP,MP_1)}{T(O_i|FP)} = \frac{0.125}{0.25} = 0.5 \]
Likelihood Example | Interpretation of Results {.build}
Most likely parent is \(MP_2\) because \(\lambda_2 = 0.5 > \lambda_1 = 0.25\).
\(\;\)
Does this mean that \(MP_2\) is the real parent?
Likelihood Example | In Class Exercise - Whose the daddies?
| Individual | Locus 1 | Locus 2 | Locus 3 |
|---|---|---|---|
| Mother | \(A_1A_1\) | \(B_1B_3\) | \(C_1C_1\) |
| Offspring 1 | \(A_1A_2\) | \(B_1B_3\) | \(C_1C_2\) |
| Offspring 2 | \(A_1A_1\) | \(B_3B_3\) | \(C_1C_1\) |
| Offspring 3 | \(A_1A_1\) | \(B_1B_1\) | \(C_1C_1\) |
| Dad 1 | \(A_1A_2\) | \(B_2B_3\) | \(C_1C_1\) |
| Dad 2 | \(A_2A_2\) | \(B_1B_1\) | \(C_1C_2\) |
| Dad 3 | \(A_1A_1\) | \(B_2B_3\) | \(C_1C_2\) |
| Dad 4 | \(A_1A_1\) | \(B_1B_1\) | \(C_2C_2\) |
library(gstudio)
loci <- c("Locus-A","Locus-B","Locus-C","Locus-D")
freqs <- data.frame(Locus = rep(loci, each = 4),
Allele = rep(LETTERS[1:4], times = 4),
Frequency = 0.25)
freqs## Locus Allele Frequency
## 1 Locus-A A 0.25
## 2 Locus-A B 0.25
## 3 Locus-A C 0.25
## 4 Locus-A D 0.25
## 5 Locus-B A 0.25
## 6 Locus-B B 0.25
## 7 Locus-B C 0.25
## 8 Locus-B D 0.25
## 9 Locus-C A 0.25
## 10 Locus-C B 0.25
## 11 Locus-C C 0.25
## 12 Locus-C D 0.25
## 13 Locus-D A 0.25
## 14 Locus-D B 0.25
## 15 Locus-D C 0.25
## 16 Locus-D D 0.25adults <- make_population( freqs, N=100 )
adults$OffID <- 0
adults <- adults[ , c(1,6,2:5)]
adults[1:5,]## ID OffID Locus-A Locus-B Locus-C Locus-D
## 1 1 0 B:D A:D A:D A:B
## 2 2 0 A:B D:D B:B A:D
## 3 3 0 A:B B:C C:C A:C
## 4 4 0 C:D A:C A:B A:C
## 5 5 0 B:D A:D D:D B:Boffs <- data.frame()
mom <- adults[1,]
for( i in 1:20){
dad_id <- runif( 1, min=2, max=100)
dad <- adults[dad_id,]
off <- mate( mom, dad, N=1 )
offs <- rbind( offs, off )
}
offs$OffID <- 1:20
offs[1:5,]## ID OffID Locus-A Locus-B Locus-C Locus-D
## 1 1 1 B:D A:D C:D B:C
## 2 1 2 C:D A:D A:D B:D
## 3 1 3 B:D A:D A:B B:D
## 4 1 4 A:B A:C A:D B:B
## 5 1 5 D:D A:D A:B A:Adata <- rbind( adults, offs )
data <- data[ order(data$ID,data$OffID),]
rownames(data) <- 1:nrow(data)
data[1:10,]## ID OffID Locus-A Locus-B Locus-C Locus-D
## 1 1 0 B:D A:D A:D A:B
## 2 1 1 B:D A:D C:D B:C
## 3 1 2 C:D A:D A:D B:D
## 4 1 3 B:D A:D A:B B:D
## 5 1 4 A:B A:C A:D B:B
## 6 1 5 D:D A:D A:B A:A
## 7 1 6 B:D B:D A:B A:D
## 8 1 7 A:D A:B C:D B:C
## 9 1 8 A:D A:C A:C A:D
## 10 1 9 A:D A:D A:B A:C## Locus Pexcl PexclMax Fraction
## 1 Locus-A 0.5038453 0.5039062 0.9998791
## 2 Locus-B 0.5037248 0.5039062 0.9996400
## 3 Locus-C 0.5036015 0.5039062 0.9993953
## 4 Locus-D 0.5038453 0.5039062 0.9998791## [1] 0.9393561## ID OffID Locus-A Locus-B Locus-C Locus-D
## 2 1 1 B:D A:D C C
## 3 1 2 C A:D A:D D
## 4 1 3 B:D A:D B D
## 5 1 4 A C A:D B
## 6 1 5 D A:D B A
## 7 1 6 B:D B B D
## 8 1 7 A B C C
## 9 1 8 A C C D
## 10 1 9 A A:D B C
## 11 1 10 B:D D A:D A:B
## 12 1 11 A A B D
## 13 1 12 C A A:D D
## 14 1 13 D A:D A:D C
## 15 1 14 D C B B
## 16 1 15 D B C A
## 17 1 16 D A:D B C
## 18 1 17 B:D D A D
## 19 1 18 B C D A:B
## 20 1 19 D A B C
## 21 1 20 A A B Ddads <- adults[2:100,]
mom <- adults[1,]
off <- offs[1,]
for( i in 1:nrow(dads)){
dad <- dads[i,]
T <- transition_probability(off,mom,dad)
if( T > 0 )
cat("Father",i,"may be the real father (T =",T,")\n")
}## Father 16 may be the real father (T = 0.00390625 )
## Father 19 may be the real father (T = 0.015625 )
## Father 22 may be the real father (T = 0.0078125 )
## Father 25 may be the real father (T = 0.0078125 )
## Father 28 may be the real father (T = 0.00390625 )
## Father 33 may be the real father (T = 0.00390625 )
## Father 49 may be the real father (T = 0.0078125 )
## Father 50 may be the real father (T = 0.015625 )
## Father 73 may be the real father (T = 0.03125 )
## Father 76 may be the real father (T = 0.00390625 )
## Father 82 may be the real father (T = 0.00390625 )15.4 Fractional Paternity
In cases where we have more than one putative father, we may want to get an idea of the relative strength of our inferences by comparing the likelihood ratios for all dads.
- We may use arbitrary cut-offs, or
- We may use all non-excluded dads, but weighted by their fractional contributions
Conditional Probability
Problem: We have several putative fathers (\(MP_i, MP_j, MP_k, ... , MP_m\)) have been found to have non-zero likelihoods of paternity.
\(\;\)
Question: What is the relative likelihood of paternity given these putative fathers?
Conditional Probability
Conditional probability determines the likelihood of an event (paternal likelihood) given that some other event has already happened (not excluded as a potential father).
\[ P(MP=j^*|FP=i,O=k) = \frac{P(O=k|FP=i,MP=j^*)P(MP=j^*|FP=i)}{\sum_{\forall j}P(O=k|FP=i,MP=j^*)P(MP=j^*|FP=i)} \]
If we can assume that \(P(MP=j|FP=i) = c\) (e.g., the frequencies of the female and male parents are constant with respect to the individual offspring being considered) then,
\[ P(MP=j^*|FP=i,O=k) = \frac{T(\gamma_k|\alpha_i,\beta_j^*)}{\sum_{\forall k}T(\gamma_k|\alpha_i,\beta_k^*)} \]
Fractional Paternity
Some things to consider when using fractional analyses for paternity.
- Not usually used in human studies.
- Can be considered a prior probability of paternity.
- Can include ecological, spatial, evolutionary components such as differential attractiveness, pollen fertility, output, etc.
- Possible tautology
Every potential father is assigned paternity, the fraction of \(X_{ik}\) on a particular \(MP_j\) is proportional to the likelihood ratio.
## MomID OffID DadID Fij
## Min. :1 Min. : 1.000 Min. : 2.00 Min. :0.02222
## 1st Qu.:1 1st Qu.: 4.000 1st Qu.: 21.00 1st Qu.:0.06667
## Median :1 Median :10.000 Median : 45.00 Median :0.09091
## Mean :1 Mean : 9.369 Mean : 49.58 Mean :0.12500
## 3rd Qu.:1 3rd Qu.:14.000 3rd Qu.: 79.00 3rd Qu.:0.16667
## Max. :1 Max. :20.000 Max. :100.00 Max. :0.80000## MomID OffID DadID Fij
## 1 1 1 74 0.29629630
## 2 1 1 20 0.14814815
## 3 1 1 51 0.14814815
## 4 1 1 23 0.07407407
## 5 1 1 26 0.07407407
## 6 1 1 50 0.07407407
## 7 1 1 17 0.03703704
## 8 1 1 29 0.03703704
## 9 1 1 34 0.03703704
## 10 1 1 77 0.03703704##
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
## 11 14 13 10 8 6 5 7 5 15 8 9 8 2 2 8 9 8 4 8##
## One Sample t-test
##
## data: as.numeric(t)
## t = 2.5331, df = 19, p-value = 0.02027
## alternative hypothesis: true mean is not equal to 6.003747
## 95 percent confidence interval:
## 6.350553 9.649447
## sample estimates:
## mean of x
## 8Maternity Analysis
Putative father identified by mother unknown.
\[ \lambda_i = \frac{P(\gamma|\beta)P(\beta)}{P(\gamma)P{\beta})} \\ = \frac{P(\gamma|\beta)}{P(\gamma)} \]
where \(P(\gamma)\) is the frequency of the offspring genotype in the population. All other things are the same.
Cryptic Gene Flow
Consider the case where:
- You have identified a set of offspring collected from mothers.
- Identified a set of fathers that are probabilistically sires of the offspring.
15.5 Dispersal Kernels
Estimating the Disperal Distribution
Once a collection of paternity estimates have been determined, you can use them to estimate a dispersal kernel, describing the probability of paternity as a function of distance from the maternal individual.
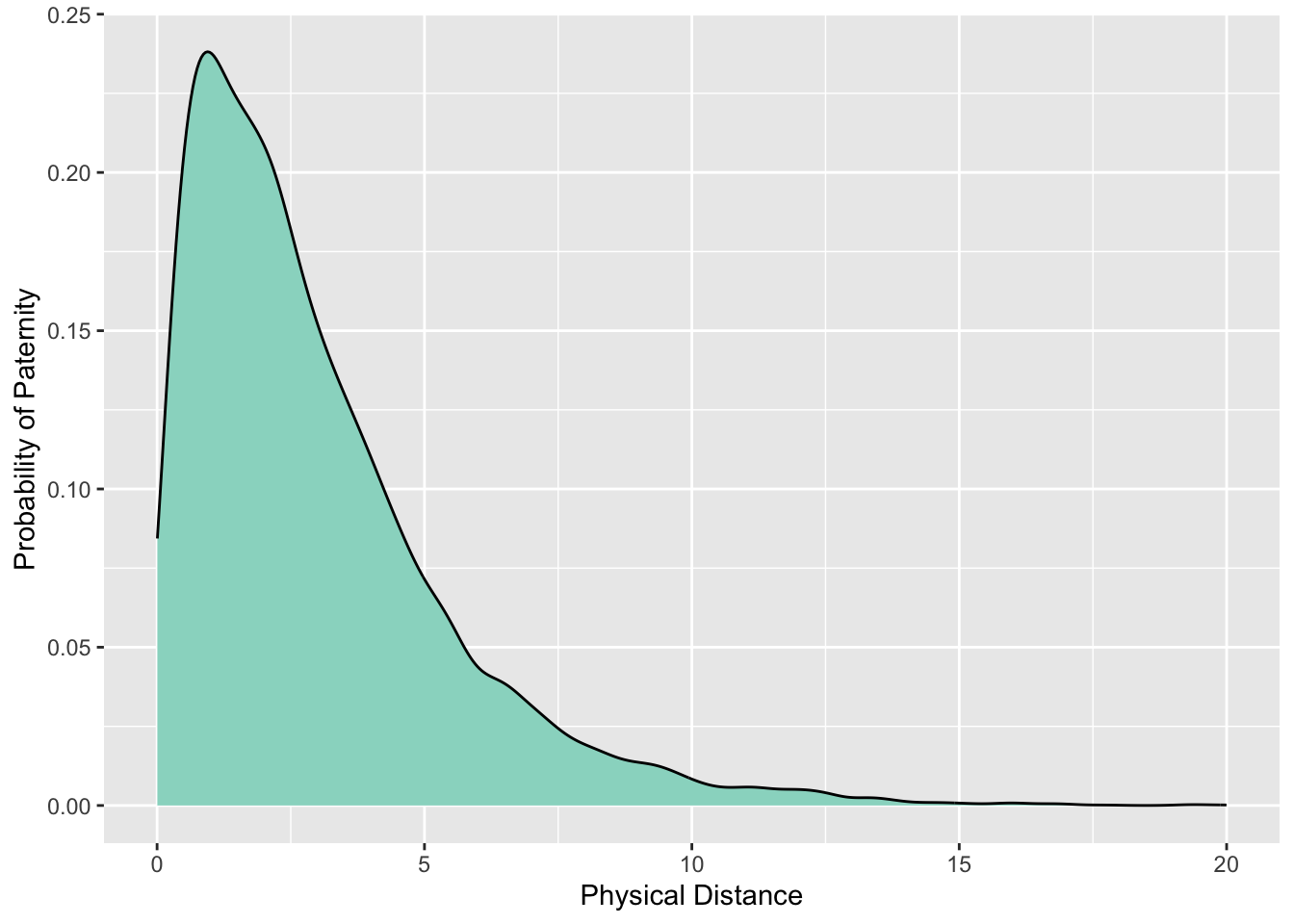
Dispersal Kernels | Distributions
The form of the distribution is critical for estimation. It determines:
- The shape of the distribution
- The variance of the distribution
- Quantitative estimates and hypotheses you get from the data
Example Kernel Distribution Families
Normal Family
\[ p(a|x,y) = \frac{1}{\pi a^2}exp\left[-\left( \frac{r}{a} \right)^2\right] \]
where \(r = \sqrt{ x^2 + y^2}\) and \(a = \sigma \sqrt{2}\).
\(\;\)
This produces a thin tailed distribution.
Example Kernel Distribution Families
Exponential Family
\[ p(a,b|x,y) = \frac{b}{2\pi a^2 \Gamma(2/b)}exp\left[ -\left( \frac{r}{a} \right)^b \right] \]
where \(\Gamma(a,b)\) is the gamma function and \(b\) is a ‘shape’ parameter.
- When \(b=1\) This is the exponential distribution.
- When \(b=2\) this is the normal function.
- When \(b<1\) this is a fat-tailed distribution.
Example Kernel Distribution Families
Other distributions you may run across include:
- The Geometric distribution,
- The Weibull family of distributions,
- The 2Dt family of distributions.
r1 <- abs(rnorm(10000))
r2 <- rexp(10000)
df <- data.frame( Distribution=c(rep(c("Normal","Exponential"),each=10000)), Value=c(r1,r2))
library(ggplot2)
ggplot(df,aes(x=Value,fill=Distribution)) + geom_density(alpha=0.75) + theme_bw() + ylab("Frequency")
Concerns with kernel estimation
The following are some assumptions that are inherent in the use of dispersal kernels for estimating connectivity.
- All functions are continuous,
- All functions assume isotropy in dispersal,
- All functions explicitly assume homogeneity of the dispersal matrix.
Skills
In this lecture we covered some rather simple parent/offspring relationships and how we can analyze them. Specifically, you should be comfortable with:
- Understanding the qualities of loci that make for more powerful parentage analyses.
- Be able to estimate single and multilocus exclusion probabilities and understand what they mean.
- Estimate likelihood ratios for paternity given Mother, Offspring, and Putative Male Parent.
- Use fractional paternity and understand conditional probability and how it applies to parentage.
- Understand dispersal kernel estimation.