4 Manipulating Data
The sine qua non of of this course is instruction in how how to manipulate data. In this class activity, we will focus on some built-in data sets to allow you to work in R and get more keyboard time in RStudio. There will be a series of questions at the end of the lecture that will ask you to retrieve certain information from various data sets.
4.1 Data Import & Export
Raw data is imported into R using read.* functions. There are a wide variety of file formats available, most of which have a corresponding function (e.g., read.csv(), read.delim(), read.dcf(), etc.). For our purposes, we will focus on using comma separated files (*.CSV) as they are the most readily available and can be read by almost all editors and spreadsheet functions.
On the lecture webpage, there is a file named iris.csv. Download this file and put it in the same directory as your RStudio session. If you do not know where this is, you can find it by asking R to get its current working directory as:
getwd()## [1] "/Users/rodney/Documents/Teaching/EnvironmentalDataLiteracy"The same information is also printed across the top of the “Files” pane in the RStudio interface (though it starts from your ‘home’ directory instead of the top of the file path).

One way to easily open this location is to select the “Show Folder in New Window” menu item in the “More” menu on that same pane. It will open the folder you are looking at in the file system as a new window for you, then you can drag and drop things into it.
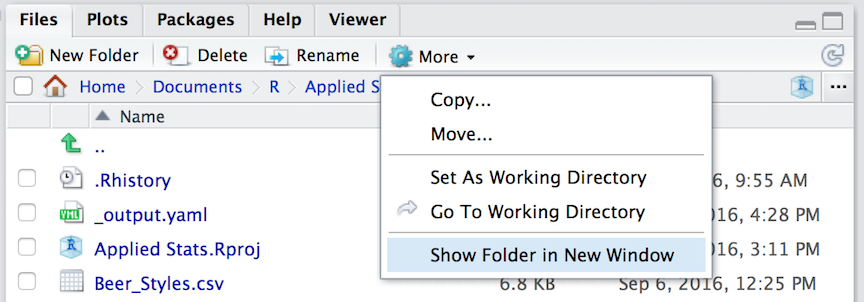
Keep in mind that R is running in a specific location on your computer. This working directory is where it looks for stuff if you do not give a complete file path (e.g., ‘C:\Users...’ or ‘/Users/…’ on winblows and mac, respectively). To load in a CSV file, we can use the function
data <- read.csv("file.csv")where at a bare minimum, we need to have the name of the file (in the example above it was ‘file.csv’). There are a lot of additional arguments you can pass to read.csv() including:
header = TRUE: Does the file have a header row that gives the variable names?sep = ",": What is the column separator. By default for CSV, it is a comma.quote = "\"": Is there text that is quoted within the body of the document?dec = ".": What is the decimal character?fill = TRUE: Do you want to fill in the empty data cells or do all rows of data have the same amount of data.comment.char = "": Are there comments in the text?
Additional options are available if you look at the help file as:
?read.csvOnce you have read the file in (it will complain with an error message if it does not work), then you will have a data.frame object named data (from the example above, you should of course name it something more descriptive).
\(\;\)
Saving materials in R is a bit easier. If you are needing to export the file back into a CSV format then you can use write.csv() (see ?write.csv for specifics and examples) and it will write the file as a text file. However, if you are only working in R with that file, you can save it as an R object without translating it back and forth through a CSV file. Using the example data from above, you could save the data.frame as an R data object using:
save( data, file="mydata.rda")and it will save the object. Next time you need it, you can load it in using:
load("mydata.rda")4.2 Diving Into Data
In this next section, we will walk through the example iris data set and highlight some of the ways that you can manipulate data.frame objects. If you have loaded in the data set as outlined above, we should be able to get a first look at it using the summary() function.
summary(flowers)## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
## Median :5.800 Median :3.000 Median :4.350 Median :1.300
## Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
## Species
## setosa :50
## versicolor:50
## virginica :50
##
##
## Each of the columns in the data.frame is named, the first four of which are numerical values and the last one is a species designation.
4.3 Factor & Character Data
Depending upon how you have set up your R session, the last column may be either a character type or a factor. By default, some builds of R turn all string characters into factors (a behavior I do not like because there are a lot of data types that I load in that are best defined as non-factors).
In this data set though, it is probably best if the Species column were really a factor and not just a character data type. We will play with this data set a bit and we will use the Species as a defining category (i.e., a factor).
flowers$Species <- factor( flowers$Species )
summary(flowers)## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
## Median :5.800 Median :3.000 Median :4.350 Median :1.300
## Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
## Species
## setosa :50
## versicolor:50
## virginica :50
##
##
## Notice in the output above how the factor column is tabulated by a count of the number of observations whereas the summary of the character data is just lumped all together. Also remember, if you do not specify the factors as ordered=TRUE then it will assume that they are categorical data without ordinal information. In this case, there is no reason to assume that one of these species types is greater than or less than another one so these are unordered factors.
Conversely, if you have imported some data and it was automatically interpreted as factors, you can change a factor back to a character type by using the as.character() function. I find in my interactions with data, I use a lot more textual data than factors so I set the default up to not automatically translate it into factors, only doing so when I need to.
In the example above, I replaced the original column of data with the factor version, though you may not need to do that. You can easily add another column of data to the data.frame giving it a new name. In the example below, I take the flowers$Species column and make a new one named Taxonomy by pasting the genus of the flowers onto it.
flowers$Taxonomy <- paste( "Iris", flowers$Species )
summary(flowers)## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
## Median :5.800 Median :3.000 Median :4.350 Median :1.300
## Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
## Species Taxonomy
## setosa :50 Length:150
## versicolor:50 Class :character
## virginica :50 Mode :character
##
##
## 4.4 Indexing
The normal workflow in R consists of loading data into your session, manipulating the data, and performing operations—statistical, summary, or graphical–on it (or some subset of it). Each element in the data.frame is indexed by the row and column number. The order of the columns is as shown or can be viewed using
names(flowers)## [1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width"
## [5] "Species" "Taxonomy"So if we wanted to access the Sepal.Width of 3\(^{rd}\) observation, we could use the numerical indices (where the “Sepal.Width” is the second name in this list):
flowers[3,2]## [1] 3.2or by accessing the 3\(^{rd}\) element of the “Sepal.Width” vector.
flowers$Sepal.Width[3]## [1] 3.2If you pull observations from a data.frame, you either get a new data.frame (if you include more than one column)
df <- flowers[,c(2,3,5)]
class(df)## [1] "data.frame"summary(df)## Sepal.Width Petal.Length Species
## Min. :2.000 Min. :1.000 setosa :50
## 1st Qu.:2.800 1st Qu.:1.600 versicolor:50
## Median :3.000 Median :4.350 virginica :50
## Mean :3.057 Mean :3.758
## 3rd Qu.:3.300 3rd Qu.:5.100
## Max. :4.400 Max. :6.900or a vector of data (if you only have one column or any subset of one column).
sepal_width <- flowers$Sepal.Width
length(sepal_width)## [1] 150class(sepal_width)## [1] "numeric"sepal_width## [1] 3.5 3.0 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 3.7 3.4 3.0 3.0 4.0 4.4 3.9
## [18] 3.5 3.8 3.8 3.4 3.7 3.6 3.3 3.4 3.0 3.4 3.5 3.4 3.2 3.1 3.4 4.1 4.2
## [35] 3.1 3.2 3.5 3.6 3.0 3.4 3.5 2.3 3.2 3.5 3.8 3.0 3.8 3.2 3.7 3.3 3.2
## [52] 3.2 3.1 2.3 2.8 2.8 3.3 2.4 2.9 2.7 2.0 3.0 2.2 2.9 2.9 3.1 3.0 2.7
## [69] 2.2 2.5 3.2 2.8 2.5 2.8 2.9 3.0 2.8 3.0 2.9 2.6 2.4 2.4 2.7 2.7 3.0
## [86] 3.4 3.1 2.3 3.0 2.5 2.6 3.0 2.6 2.3 2.7 3.0 2.9 2.9 2.5 2.8 3.3 2.7
## [103] 3.0 2.9 3.0 3.0 2.5 2.9 2.5 3.6 3.2 2.7 3.0 2.5 2.8 3.2 3.0 3.8 2.6
## [120] 2.2 3.2 2.8 2.8 2.7 3.3 3.2 2.8 3.0 2.8 3.0 2.8 3.8 2.8 2.8 2.6 3.0
## [137] 3.4 3.1 3.0 3.1 3.1 3.1 2.7 3.2 3.3 3.0 2.5 3.0 3.4 3.0In addition to numerical values, you can also use logical statements to select subsets of your data. Here is an example of all the data whose flowers$Sepal.Width is less than 3.0cm and those that have sepals as large or bigger than 3.0cm.
small_sepals <- flowers[ flowers$Sepal.Width < 3.0, ]
big_sepals <- flowers[ flowers$Sepal.Width >= 3.0, ]
summary( small_sepals )## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.400 Min. :2.00 Min. :1.300 Min. :0.200
## 1st Qu.:5.600 1st Qu.:2.50 1st Qu.:4.000 1st Qu.:1.200
## Median :6.000 Median :2.70 Median :4.500 Median :1.400
## Mean :5.953 Mean :2.64 Mean :4.509 Mean :1.449
## 3rd Qu.:6.300 3rd Qu.:2.80 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :7.700 Max. :2.90 Max. :6.900 Max. :2.400
## Species Taxonomy
## setosa : 2 Length:57
## versicolor:34 Class :character
## virginica :21 Mode :character
##
##
## summary( big_sepals )## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.300 Min. :3.000 Min. :1.000 Min. :0.100
## 1st Qu.:5.000 1st Qu.:3.000 1st Qu.:1.500 1st Qu.:0.200
## Median :5.600 Median :3.200 Median :1.900 Median :0.500
## Mean :5.776 Mean :3.313 Mean :3.298 Mean :1.046
## 3rd Qu.:6.500 3rd Qu.:3.500 3rd Qu.:5.200 3rd Qu.:1.800
## Max. :7.900 Max. :4.400 Max. :6.700 Max. :2.500
## Species Taxonomy
## setosa :48 Length:93
## versicolor:16 Class :character
## virginica :29 Mode :character
##
##
## There are two ways you can also merge data.frame objects. You can add data onto the bottom of the data.frame by using the rbind() function (row-binding). This requires that both data.frame objects have the same column names (and in the same order).
all_sepals <- rbind( small_sepals, big_sepals )
summary( all_sepals )## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
## Median :5.800 Median :3.000 Median :4.350 Median :1.300
## Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
## Species Taxonomy
## setosa :50 Length:150
## versicolor:50 Class :character
## virginica :50 Mode :character
##
##
## You can also merge together two data.frames that have a common column index. This may be necessary for cases where you have different kinds of observations that need to be merged into a single data.frame.
Here is an example where I have some data on my sampling sites
sites <- data.frame( Site=c("Olympia","Richmond"),
Latitude=c(47.0379,37.5407),
Longitude=c(122.9007,77.4360) )
sites## Site Latitude Longitude
## 1 Olympia 47.0379 122.9007
## 2 Richmond 37.5407 77.4360and another set of data that has some observations on samples taken from each site.
data <- data.frame( Site=c("Olympia","Olympia","Olympia","Richmond","Richmond"))
data$Measurement <- c(12,22,35,56,46)
data## Site Measurement
## 1 Olympia 12
## 2 Olympia 22
## 3 Olympia 35
## 4 Richmond 56
## 5 Richmond 46If I wanted to merge these two data.frame objects into a single one, incorporating each of the columns of data in both, I would
df <- merge( sites, data )
df## Site Latitude Longitude Measurement
## 1 Olympia 47.0379 122.9007 12
## 2 Olympia 47.0379 122.9007 22
## 3 Olympia 47.0379 122.9007 35
## 4 Richmond 37.5407 77.4360 56
## 5 Richmond 37.5407 77.4360 46Here the merge() function looks for a column that has the same name in both data.frame objects. In this case it was “Site”. It then uses that as an index to merge both together into a new object.
4.5 Sorting & Ordering
The order in which rows of observations are in the data.frame is determined by their placement in the original file. If you look at the data, it seems to be sorted by flowers$Species but nothing after that.
head(flowers)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species Taxonomy
## 1 5.1 3.5 1.4 0.2 setosa Iris setosa
## 2 4.9 3.0 1.4 0.2 setosa Iris setosa
## 3 4.7 3.2 1.3 0.2 setosa Iris setosa
## 4 4.6 3.1 1.5 0.2 setosa Iris setosa
## 5 5.0 3.6 1.4 0.2 setosa Iris setosa
## 6 5.4 3.9 1.7 0.4 setosa Iris setosaYou can sort the whole data.frame by asking for a copy of it with a specific order based upon the columns. Here I will re-assign the data.frame but this time ordered by flowers$Sepal.Length.
flowers <- flowers[ order(flowers$Sepal.Length), ]
head(flowers)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species Taxonomy
## 14 4.3 3.0 1.1 0.1 setosa Iris setosa
## 9 4.4 2.9 1.4 0.2 setosa Iris setosa
## 39 4.4 3.0 1.3 0.2 setosa Iris setosa
## 43 4.4 3.2 1.3 0.2 setosa Iris setosa
## 42 4.5 2.3 1.3 0.3 setosa Iris setosa
## 4 4.6 3.1 1.5 0.2 setosa Iris setosaNote the row indices (the column on the far left), they indicate the original order in which the observations were put into the data.frame. The smallest sepal length in the data set was originally the 14\(^{th}\) observation.
You see from the example above that the addition of new columns to a data.frame result in them being put on the right-hand side data.frame (e.g., flowers$Taxonomy is the last column of the output). If you want to rearrange the columns of the data.frame, you do so by manually re-arranging the indices on those columns. For example, if I wanted to make the numerical data the last four columns instead of the first two, I would specify it as:
flowers <- flowers[ , c(6,5,1,2,3,4) ]
summary(flowers)## Taxonomy Species Sepal.Length Sepal.Width
## Length:150 setosa :50 Min. :4.300 Min. :2.000
## Class :character versicolor:50 1st Qu.:5.100 1st Qu.:2.800
## Mode :character virginica :50 Median :5.800 Median :3.000
## Mean :5.843 Mean :3.057
## 3rd Qu.:6.400 3rd Qu.:3.300
## Max. :7.900 Max. :4.400
## Petal.Length Petal.Width
## Min. :1.000 Min. :0.100
## 1st Qu.:1.600 1st Qu.:0.300
## Median :4.350 Median :1.300
## Mean :3.758 Mean :1.199
## 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :6.900 Max. :2.5004.6 Manipulating Data
As we saw above, you can change data either in-place or by adding new columns (and you could also drop columns by reordering them and just not include all the columns in the column indices). You can also perform operations on columns of data, again either in-place, as an additional column, or not connected at all with the data.frame. To do it in-place, you simply re-assign the values after the calculation. For example, here is how I would subtract the average “Sepal.Length” from all the observations.
ave_sepal_length <- mean( flowers$Sepal.Length )
standardized_sepal_lengths <- flowers$Sepal.Length - ave_sepal_length
summary( standardized_sepal_lengths )## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -1.54300 -0.74330 -0.04333 0.00000 0.55670 2.05700Which should have a mean of zero, right?
\(\;\)4.7 Tabulating
We can finish up this exploration of the iris data set by doing some summaries. One of the main strengths of R is that it is a functional language. This may not mean much to you now, but in the long run you will find that you can perform opertions on large data sets by merging together cleaver use of indices and the application of one or more functions.
Consider the case where we are trying to find the mean for each of the three species. Proceedurally, we must do the following general steps:
- Go through each row of the data and figure out which species we are looking at.
- Add the length of this observation to a tally variable, one for each species.
- Count how many observations of each species we have in the
data.frame. - Divide the approporiate tally variable by the number of observations.
- Return or print out the results.
Not a trivial thing to do. If you were going to to this literally, you would have to set up three tally variables, three observation count variables, and then do a loop and run through all the observations making decisions on which observation is which and where to add the tally and count.
Fortunately for us, this is not that difficult of an issue in R for the following two reasons:
1. We have a function mean() that estimates the mean of a set of variables. 2. We have a factor varaible in flowers that differentiates between species.
As such we can then ask R to estimate the mean in “Sepal.Length” by “Species” using
mean_sepal_length <- by( flowers$Sepal.Length, flowers$Species, mean)
mean_sepal_length## flowers$Species: setosa
## [1] 5.006
## --------------------------------------------------------
## flowers$Species: versicolor
## [1] 5.936
## --------------------------------------------------------
## flowers$Species: virginica
## [1] 6.588If you read this literally, it says, “Wit Sepal Length, partition the data by Species and pass it to the function mean”. This shorthand is important in that it highlights the flexibility and utility of applying functions to our data. With a few keystrokes, we can accomplish a lot of computational progress!
You could find these values by slicing as:
# literally grab the mean of all sepal lengths WHERE species is identical to X
mean_setosa <- mean( flowers$Sepal.Length[ flowers$Species == "setosa" ] )
mean_versicolor <- mean( flowers$Sepal.Length[ flowers$Species == "versicolor" ] )
mean_virginica <- mean( flowers$Sepal.Length[ flowers$Species == "virginica" ] )
mean_sepal_lengths_long <- c(setosa=mean_setosa, versicolor=mean_versicolor, virginica=mean_virginica )
mean_sepal_lengths_long## setosa versicolor virginica
## 5.006 5.936 6.588But it sure does look like a lot more code to write! In general, we should strive to keep our code as easy to understand as possible. In the end, you will be reading your own code and you must be able to easily understand it at some random time in the future. For this to happen, you really need to clear on what you are trying to do.
\(\;\)